
Als Online-Unternehmer oder Blogger stehst du vor einer neuen Herausforderung.
Webcrawler von OpenAI, Anthropic oder Google durchsuchen das Web und sammeln Trainingsdaten für LLMs und andere KI-Modelle.
Deine wertvollen Blogbeiträge, die du mit viel Mühe erstellt hast, könnten so ohne dein Wissen und deine Zustimmung für KI-generierte Texte in ChatGPT & Co. verwendet werden.
Das kann nicht nur deine Urheberrechte verletzen, sondern auch deine Wettbewerbsposition gefährden. Irgendwie beunruhigend, oder?
Vielleicht fragst du dich schon, wie du deine Arbeit schützen kannst. Wie verhinderst du, dass deine Inhalte ohne dein Einverständnis für KI-Training verwendet werden?
Kein Problem!
In diesem Artikel zeige ich dir einfach und Schritt für Schritt, wie du deine robots.txt konfigurierst, um deine Inhalte zu schützen.
- Erstelle oder bearbeite deine robots.txt, um spezifische KI-Crawler wie GPTBot, ClaudeBot, Claude-User, Claude-SearchBot, Google-Extended und Applebot-Extended zu blockieren
- Nutze selektives Blockieren, um nur bestimmte Bereiche zu schützen, während andere zugänglich bleiben
- Teste deine Konfiguration mit der Google Search Console und kombiniere robots.txt mit einer WAF (z. B. Cloudflare AI-Bot-Blockierung), da Grok und Perplexity-User robots.txt teils ignorieren
1. Vorbereitung
Bevor wir loslegen und deine Website vor neugierigen KI-Crawlern schützen, musst du ein paar Vorbereitungen treffen. Keine Sorge, es ist einfacher, als du vielleicht denkst!
Zugriff auf den Webserver
Zunächst brauchst du Zugang zu deinem Webserver. Das klingt technisch, ist aber oft nur ein Login in dein Hosting-Konto.
Wenn du WordPress nutzt, kannst du über FTP oder das File Manager Plugin direkt auf deine Dateien zugreifen.
Backup der bestehenden robots.txt
Sicherheit geht vor! Falls du schon eine robots.txt-Datei hast, mach unbedingt eine Kopie davon. So kannst du im Notfall immer zur alten Version zurückkehren.
- Suche die robots.txt-Datei im Hauptverzeichnis deiner Website
- Lade sie auf deinen Computer herunter oder kopiere den Inhalt in ein Textdokument
- Speichere diese Sicherung an einem sicheren Ort
2. Erstellung/Bearbeitung der robots.txt
Du musst kein Programmiergenie sein, um deine robots.txt-Datei zu erstellen oder zu bearbeiten.
Dafür sind nur wenige Schritte erforderlich.
2.1 Öffnen oder Erstellen der Datei
Zunächst musst du prüfen, ob auf deiner Website bereits eine robots.txt existiert. Dafür gibt’s einen einfachen Trick.
- Öffne deinen Browser
- Gib deine Domain ein, gefolgt von „/robots.txt“ (z. B. www.deinewebsite.de/robots.txt)
- Siehst du Text? Super, die Datei existiert bereits. Wenn nicht, erstellen wir eine neue.
Falls du eine neue Datei anlegen musst, gehst du so vor.
- Öffne einen einfachen Texteditor (Notepad, TextEdit, etc.)
- Erstelle ein neues, leeres Dokument
- Speichere es als „robots.txt“ (Achtung: keine Dateiendung wie .txt anhängen!)
2.2 Grundstruktur anlegen
Die robots.txt folgt einer bestimmten Syntax (Aufbau). Hier die Basics:
User-agent: [Name des Crawlers]
Disallow: [Pfad, der blockiert werden soll]Für den Anfang könntest du so etwas schreiben.
User-agent: *
Disallow:Das bedeutet: Alle Crawler (*) dürfen alles crawlen (leeres „Disallow“). Das ist unser Ausgangspunkt, von dem aus wir die Datei weiter anpassen werden.
3. Blockieren spezifischer KI-Crawler
Um gängige KI-Crawler zu blockieren, musst du folgende Blöcke in deine robots.txt einfügen:
OpenAI (ChatGPT)
OpenAI hat insgesamt drei verschiedene Crawler, die verschiedene Funktionen erfüllen. Um Content-Diebstahl möglichst effektiv zu verhindern, solltest du alle ausschließen.
User-agent: OAI-SearchBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: GPTBot
Disallow: /Anthropic (Claude)
Anthropic dokumentiert seit Anfang 2026 vier Bots: ClaudeBot (Modelltraining), Claude-User (Live-Anfragen aus Claude an dein Live-Web), Claude-SearchBot (Indexierung für die In-Claude-Websuche) und claude-code (Claude Code CLI). Die alten User-Agents Claude-Web und anthropic-ai sind offiziell deprecated, viele Crawler senden sie aber noch. Du blockierst am besten alle:
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
User-agent: claude-code
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /Google (Gemini)
User-agent: Google-Extended
Disallow: /Common Crawl
User-agent: CCBot
Disallow: /Perplexity
Perplexity nutzt zwei Bots: PerplexityBot für Indexierung und Perplexity-User für nutzergesteuerte Anfragen. Achtung: Perplexity-User ignoriert laut Perplexity ausdrücklich robots.txt, da er als „nutzergetrieben“ gilt. Eine zusätzliche WAF-/Firewall-Regel ist hier oft sinnvoll.
User-agent: PerplexityBot
Disallow: /
User-agent: Perplexity-User
Disallow: /Meta AI / Facebook
User-agent: FacebookBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /Webz.io
User-agent: OmgiliBot
Disallow: /Cohere
User-agent: cohere-ai
Disallow: /xAI/SpaceXAI (Grok)
xAI gehört seit Februar 2026 zu SpaceX und firmiert inzwischen als SpaceXAI, dokumentiert aber weiterhin offiziell drei User-Agents (GrokBot/1.0, xAI-Grok/1.0 und Grok-DeepSearch/1.0). In der Praxis tarnt sich Grok jedoch häufig als normaler Browser oder als Go-http-client/1.1, sodass robots.txt-Regeln oft ins Leere greifen. Trag die offiziellen Strings trotzdem ein, ergänze sie aber durch eine Firewall-Regel oder Cloudflare-AI-Bot-Blockierung:
User-agent: GrokBot
Disallow: /
User-agent: xAI-Grok
Disallow: /
User-agent: Grok-DeepSearch
Disallow: /Apple (Apple Intelligence)
Applebot-Extended kontrolliert ausschließlich, ob Apple deine Inhalte für das Training von Apple Intelligence verwenden darf. Der reguläre Applebot für Spotlight und Siri-Vorschläge bleibt davon unberührt. Mit dem Rollout von Apple Intelligence ist Applebot 2026 zu einem der aktivsten KI-Crawler aufgestiegen.
User-agent: Applebot-Extended
Disallow: /Amazon
Amazonbot sammelt Inhalte für Alexa, Echo und Amazons interne KI-Shopping-Assistenten. Amazon dokumentiert IP-Ranges sauber und respektiert robots.txt zuverlässig.
User-agent: Amazonbot
Disallow: /4. Selektives Blockieren
Manchmal willst du KI-Crawler nicht komplett aussperren, sondern nur bestimmte Bereiche deiner Website schützen.
Kein Problem!
Bestimmte Verzeichnisse/Seiten sperren
Wenn du einen Bereich mit exklusiven Inhalten hast, kannst du diesen mit folgendem Code von Crawlern ausschließen:
User-agent: GPTBot
Disallow: /exklusiv/
User-agent: anthropic-ai
Disallow: /premium-content/In diesem Beispiel blockierst du GPTBot von deinem „/exklusiv/“-Verzeichnis und Anthropics Crawler von „/premium-content/“.
Ausnahmen definieren
Manchmal möchtest du vielleicht den Großteil deiner Seite blockieren, aber bestimmte Bereiche für KI-Crawler zugänglich machen. Hier ein Beispiel:
User-agent: GPTBot
Disallow: /
Allow: /blog/
User-agent: anthropic-ai
Disallow: /
Allow: /oeffentlich/In diesem Fall blockierst du zunächst alles mit Disallow: /, erlaubst dann aber spezifische Bereiche mit Allow.
GPTBot darf also deinen Blog crawlen, während Anthropics Crawler nur auf den öffentlichen Bereich zugreifen kann.
5. Überprüfung und Testen
Alles eingerichtet? Super!
Aber bevor du dich zurücklehnst, solltest du sicherstellen, dass deine robots.txt auch wirklich das tut, was sie soll.
Google stellt dir dafür ein tolles Werkzeug zur Verfügung, den robots.txt-Tester in der Google Search Console.
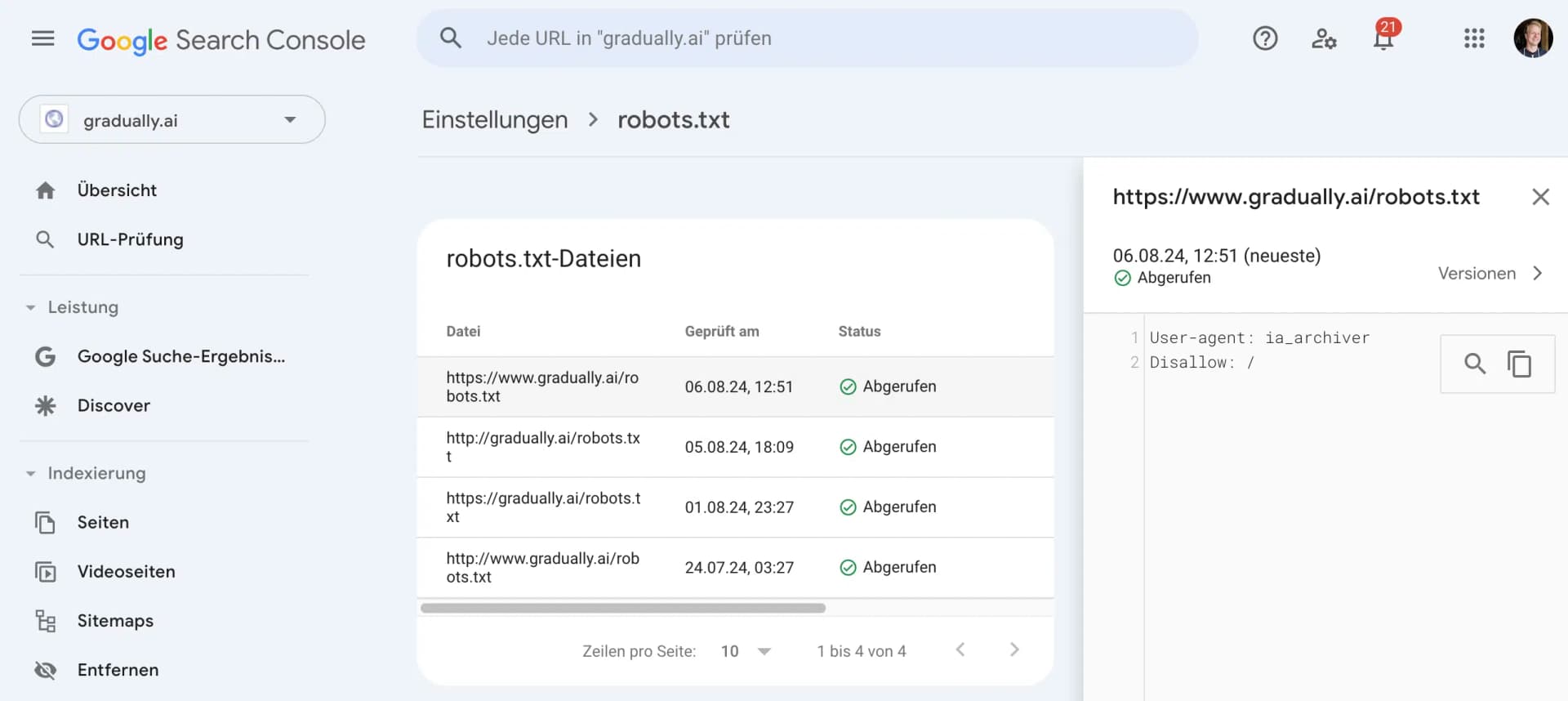
Hier kannst du sehen, ob deine robots.txt richtig von Google abgerufen kann und ob sie Fehler beinhaltet.





