
Es gibt mittlerweile hunderte KI-Stimmen-Generatoren. Und ehrlich gesagt:
Die meisten Listen im Netz werfen sie einfach in einen Topf und küren irgendein „bestes“ Tool, das für deinen konkreten Fall vielleicht gar nicht passt.
Das Problem dabei?
Ein YouTuber, der schnell ein Voiceover braucht, hat ganz andere Anforderungen als ein Entwickler, der eine datenschutzfreundliche Lösung selbst hosten will. Und wer nur ab und zu einen Text vorlesen lassen möchte, braucht keinen 99-$-Tarif.
Deshalb sortiere ich dir in diesem Überblick 18 KI-Stimmen-Generatoren nicht nach Rang, sondern nach Einsatzzweck: Premium, kostenlos, Open Source und Spezialfälle. Zu jedem Tool bekommst du ein, zwei Sätze, damit du sofort weißt, ob es zu dir passt.
- ElevenLabs ist die vielseitigste Plattform: ausdrucksstarke Stimmen (Eleven v3 mit Audio Tags), Voice Cloning, Speech-to-Text und lizenzsaubere Musik in einem Tool
- Kostenlos starten geht über Free-Tarife (ElevenLabs, Murf.ai), reine Gratis-Dienste (TTSMaker, Edge) oder Open-Source-Modelle (Coqui XTTS, Kokoro)
- Den direkten Praxistest der sechs wichtigsten Premium-Tools findest du in meinem Vergleich der besten KI-Sprachgeneratoren
1. Premium- und Profi-Tools
Diese Tools laufen in der Cloud, sind sofort einsatzbereit und liefern die natürlichsten Stimmen, die du aktuell bekommen kannst. Du zahlst monatlich, sparst dir dafür aber jede Einrichtung. Wenn du regelmäßig professionelle Audios produzierst, fängst du hier an.
ElevenLabs (meine Top-Empfehlung)
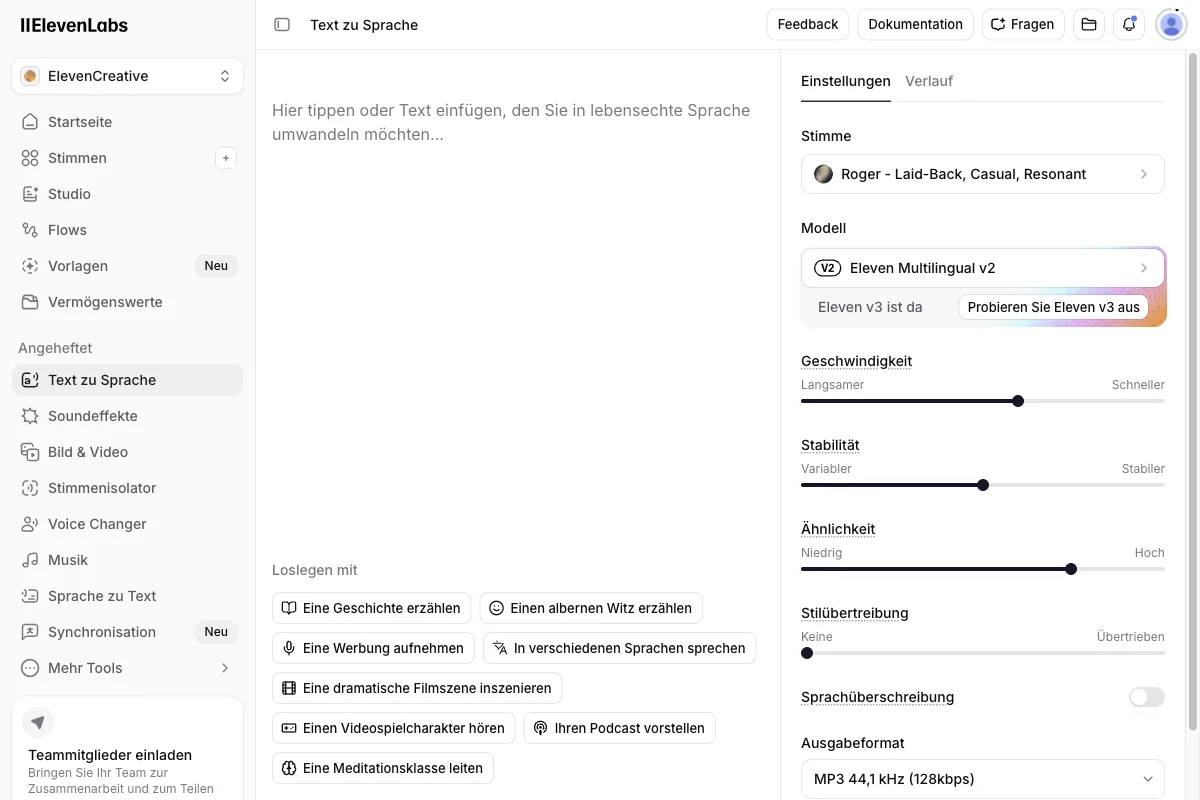
ElevenLabs ist für mich der vielseitigste KI-Stimmen-Generator auf dem Markt, und der Grund ist einfach: Aus dem einstigen Text-to-Speech-Tool ist längst eine komplette Audio-Plattform geworden.
Den Ausschlag geben zwei Neuerungen aus dem Jahr 2026.
Seit März 2026 ist das Flaggschiff-Modell Eleven v3 allgemein verfügbar. Es unterstützt über 70 Sprachen, deutlich emotionalere Stimmen und sogenannte „Audio Tags“ wie [whispers], [laughs] oder [excited], mit denen du Betonung, Emotion und Pausen direkt im Text steuerst. Du schreibst quasi Regieanweisungen in eckigen Klammern, und die Stimme setzt sie um. Das kann kein anderes Tool in dieser Form.
Dazu kommt seit Mai 2026 Music v2, ein Musikgenerator, der ausschließlich auf lizenzierten Daten trainiert wurde. Damit ist er das einzige KI-Musik-Tool, das du ohne Lizenzsorgen kommerziell nutzen kannst. ElevenLabs deckt damit von der Stimme über die Vertonung bis zur Hintergrundmusik fast die gesamte Audioproduktion ab.
Und es bleibt nicht bei Sprache und Musik. Die Plattform bündelt mehrere Werkzeuge unter einem Login:
- Text-to-Speech: über 70 Sprachen, Tausende vorgefertigte Stimmen, ausdrucksstark dank Eleven v3.
- Voice Cloning: Instant Voice Clone bereits im Starter-Tarif, professionelles Klonen im Creator-Tarif.
- Speech-to-Text: das Modell Scribe Realtime v2 transkribiert 92 Sprachen.
- Dubbing: automatische Synchronisierung von Videos, aktuell als Dubbing v2 im Alpha-Stadium mit 92 unterstützten Sprachen.
- Voice Agents: sprechende KI-Assistenten für Support oder Telefonie.
Ich habe ElevenLabs selbst auf dem Creator-Tarif getestet, mit echtem Account und echten Credits. Am meisten überzeugt hat mich die schiere Auswahl in der Stimmen-Bibliothek, die ich beim Testen direkt vor mir hatte.
Beim Preis ist der Einstieg fair. Es gibt einen kostenlosen Tarif mit 10.000 Credits pro Monat zum Testen. Der Starter-Tarif kostet 6 $ im Monat und schaltet das sofortige Voice Cloning frei. Für ernsthafte Produktion ist der Creator-Tarif für 22 $ im Monat (im ersten Monat 11 $) der ideale Einstieg: Hier bekommst du professionelles Voice Cloning und die höchste Audioqualität.
- Ausdrucksstärkste Stimmen dank Eleven v3 und Audio Tags
- Komplette Audio-Plattform: TTS, Voice Cloning, Speech-to-Text, Dubbing, Musik
- Lizenzsaubere Musik dank Music v2 (nur auf lizenzierten Daten trainiert)
- Sehr gute deutsche Sprachqualität bei den Premium-Stimmen
- Kostenloser Tarif zum Testen, Einstieg ab 6 $ pro Monat
Du willst tiefer einsteigen? Ich habe ElevenLabs in eigenen ElevenLabs-Erfahrungen ausführlich getestet, die ElevenLabs-Preise im Detail aufgeschlüsselt und passende ElevenLabs-Alternativen verglichen.
Murf.ai
Murf.ai ist die erste Wahl, wenn du im Bereich E-Learning, Erklärvideos oder Unternehmenspräsentationen unterwegs bist. Die Premium-Stimmen sind erstklassig, und die feinen Einstellmöglichkeiten für Tonhöhe und Pausenlänge pro Sprachblock sind im Profi-Einsatz Gold wert.
Einziges Manko: Die Auswahl an deutschen Stimmen ist mit wenigen Premium-Optionen überschaubar. Für saubere, ruhige Sprecher-Stimmen reicht das aber locker.
Fliki
Fliki ist mein Alltags-Favorit für Social-Media-Videos. Es bietet eine riesige Auswahl an deutschen Stimmen (aktuell 42, davon viele Premium- und Studio-Stimmen) und kombiniert die Sprachgenerierung direkt mit einem Videoeditor. Voice Cloning ist bereits im Standard-Tarif für 28 $ im Monat dabei.
Wenn du aus einem Blogartikel in einem Rutsch ein fertiges Kurzvideo machen willst, ist Fliki kaum zu schlagen.
Cartesia
Cartesia ist der Newcomer in dieser Runde und kommt aus der Entwickler-Ecke. Das hauseigene Sonic-Modell erzeugt sehr natürliche Stimmen mit extrem niedriger Latenz, also nahezu in Echtzeit. Voice Cloning ist mit an Bord.
Die Oberfläche ist schlanker als bei Murf oder Fliki und klar auf Tempo und Integration in eigene Anwendungen ausgelegt. Stark, wenn du Stimmen in eine App oder einen Sprachassistenten einbauen willst. Für klassische Voiceover-Produktion am Schreibtisch sind die anderen Premium-Tools die runderen Pakete.
Descript
Descript ist weniger ein klassischer Stimmen-Generator als ein kompletter Audio- und Video-Editor mit KI-Stimme an Bord. Das Highlight:
Du bearbeitest Audio wie ein Textdokument. Tippfehler im Skript korrigieren, Versprecher löschen, alles über den Text.
Für Podcaster und Video-Producer, die ohnehin schneiden, ist die integrierte „Overdub“-Stimme praktisch. Als reiner TTS-Generator wäre es überdimensioniert.
WellSaid Labs
WellSaid Labs ist ein US-Anbieter mit Fokus auf hochwertige englische Sprecher-Stimmen für Unternehmen und E-Learning. Das Unternehmen gehört seit 2024 zu Podcastle, das Produkt läuft aber unverändert unter wellsaid.io weiter. Die Qualität der englischen Stimmen ist exzellent und sehr konstant.
Deutsche Stimmen sind hier allerdings nicht die Stärke. Für englischsprachige Corporate-Audios eine seriöse Wahl, für deutschen Content eher nicht.
2. Kostenlose und Freemium-Tools
Nicht jeder braucht ein Abo. Wenn du nur gelegentlich einen Text vorlesen lässt oder erstmal ausprobieren willst, was KI-Stimmen draufhaben, kommst du mit diesen Optionen ohne einen Cent aus.
Speechify
Speechify ist in erster Linie eine Vorlese-App. Du lädst Bücher, PDFs oder Webseiten hoch und lässt sie dir vorlesen, auch unterwegs per App. Dazu gibt es ein AI Voice Studio für Voiceovers und Voice Cloning.
Die deutschen Stimmen sind okay, aber nicht herausragend. Als Vorlese-Tool für lange Texte ist Speechify aber super praktisch, und der kostenlose Einstieg reicht zum Antesten.
LOVO
LOVO (auch „Genny“ genannt) hat ein modernes Interface und eine solide Stimmen-Auswahl mit 19 deutschen Stimmen. Die englischen Stimmen klingen sehr gut.
Bei den deutschen Standard-Stimmen klingt es allerdings leicht monoton, und einen echten Gratis-Tarif gibt es nicht, nur einen 14-tägigen Trial. Damit eher etwas für englischsprachige Projekte.
TTSMaker
TTSMaker ist mein Geheimtipp, wenn es wirklich nichts kosten soll. Der Webdienst liest Texte ohne Anmeldung vor, im Gratis-Tarif bis zu 20.000 Zeichen pro Woche, und stellt die Ergebnisse sogar mit kommerzieller Lizenz bereit. Über 100 Sprachen sind dabei, deutsche Stimmen inklusive.
Die Qualität reicht natürlich nicht an ElevenLabs heran, ist für ein kostenloses Tool aber überraschend brauchbar. Für schnelle Voiceovers ohne Budget die erste Adresse.
Microsoft Edge (Read Aloud)
Der wohl unterschätzteste kostenlose KI-Stimmen-Generator steckt schon auf deinem Rechner. Die Vorlesefunktion „Plastisch vorlesen“ im Edge-Browser nutzt dieselben „Neural Voices“ wie Microsofts Azure-Dienst. Die deutsche Stimme klingt erstaunlich natürlich.
Du kannst zwar keine MP3 exportieren, aber zum Korrekturhören eigener Texte oder zum Vorlesen langer Artikel ist es kostenlos und sofort da.
Google Cloud Text-to-Speech
Google Cloud Text-to-Speech richtet sich an Entwickler und bietet im kostenlosen Kontingent monatlich mehrere Millionen Zeichen gratis. Die WaveNet- und Neural2-Stimmen sind sehr gut, auch auf Deutsch.
Für nicht-technische Nutzer ist die Einrichtung über die Google Cloud Console aber ziemlich sperrig. Wer programmieren kann, bekommt hier viel Qualität für null Euro.
3. Open-Source-Modelle
Für alle, die Wert auf Datenschutz und volle Kontrolle legen, kommt jetzt der interessante Teil. Diese Modelle laufen komplett lokal auf deinem Rechner. Deine Texte verlassen nie deinen Computer, es fallen keine Abo-Gebühren an, und du kannst sie nach Belieben anpassen. Der Preis dafür:
Du brauchst etwas technisches Wissen und idealerweise eine halbwegs aktuelle Grafikkarte.
Coqui XTTS
Coqui XTTS ist das wohl bekannteste Open-Source-Modell für Voice Cloning. Es klont eine Stimme aus wenigen Sekunden Audiomaterial und unterstützt 17 Sprachen, darunter Deutsch. Obwohl die Firma hinter Coqui ihren Betrieb eingestellt hat, lebt das Modell in der Community munter weiter.
Für Tüftler, die Stimmen selbst hosten und klonen wollen, ist es der Goldstandard.
Piper
Piper ist auf Geschwindigkeit und Effizienz getrimmt und läuft sogar flüssig auf einem Raspberry Pi. Die Stimmen sind nicht die ausdrucksstärksten, aber schnell, ressourcenschonend und in vielen Sprachen verfügbar.
Wenn du eine Sprachausgabe in ein eigenes Gerät oder eine Smart-Home-Lösung einbauen willst, ist Piper ideal.
Kokoro
Kokoro ist ein erstaunlich kleines Modell (nur 82 Millionen Parameter), das trotzdem überraschend natürliche Stimmen liefert und damit aktuell viel Aufmerksamkeit bekommt. Es läuft schnell, sogar ohne dicke Grafikkarte.
Wer ein leichtgewichtiges, modernes Open-Source-TTS sucht, sollte sich Kokoro ansehen.
Chatterbox
Chatterbox von Resemble AI ist eines der neuesten Open-Source-Modelle und bringt eine Besonderheit mit: eine Steuerung für die emotionale Intensität der Stimme. Damit kommt es dem ausdrucksstarken Stil der Premium-Tools näher als die meisten anderen freien Modelle.
Spannend für alle, die emotionale Stimmen lokal erzeugen wollen, ohne in die Cloud zu gehen.
4. Spezial- und Use-Case-Tools
Manche Tools sind keine klassischen Stimmen-Generatoren, lösen aber ein angrenzendes Problem so gut, dass sie hier reingehören. Wenn dein Anwendungsfall über reines Text-to-Speech hinausgeht, lohnt ein Blick.
Synthesia (KI-Stimme plus Avatar)
Synthesia kombiniert KI-Stimmen mit fotorealistischen KI-Avataren. Du tippst ein Skript, wählst einen von über 240 Avataren und bekommst ein fertiges Video, in dem eine Person deinen Text spricht. Du kannst sogar deinen eigenen Avatar mit deiner eigenen Stimme erstellen.
Für Schulungsvideos, Produktdemos oder mehrsprachige Erklärvideos ist das die naheliegende Wahl. Eine kostenlose Version (10 Minuten Video pro Monat) gibt es zum Ausprobieren.
Suno (KI-Musik mit Gesang)
Suno generiert komplette Songs inklusive gesungener Stimmen aus einem Textprompt. Du beschreibst Genre, Stimmung und Lyrics, und bekommst einen fertigen Track. Das ist faszinierend für eigene Jingles, Intros oder einfach zum Spielen.
Ein wichtiger Hinweis zur Lizenz:
Bei generierter KI-Musik gibt es nach den Rechtsstreitigkeiten der Musikindustrie offene Fragen zur kommerziellen Nutzung. Wenn du Musik geschäftlich brauchst und auf Nummer sicher gehen willst, ist die lizenzsaubere Music v2 von ElevenLabs die unkompliziertere Wahl.
Sonix (Speech-to-Text statt Text-to-Speech)
Sonix dreht den Spieß um. Statt aus Text Stimme zu machen, macht es aus Stimme Text. Der Transkriptionsdienst wandelt Audio- und Videodateien in vielen Sprachen in präzise Transkripte um, inklusive Zeitstempeln und Sprechererkennung.
Das gehört zwar nicht ins klassische TTS-Lager, ist aber genau das Werkzeug, das du brauchst, wenn du Interviews, Podcasts oder Meetings verschriftlichen willst. Sonix ist über unseren Link erreichbar.
Welcher KI-Stimmen-Generator passt zu dir?
Es kommt auf deinen Anwendungsfall an. Damit du nicht lange grübeln musst, hier meine kompakten Empfehlungen:
- Du willst die beste Qualität und Vielseitigkeit: Nimm ElevenLabs. Es deckt fast alles ab und ist meine klare Top-Empfehlung.
- Du machst E-Learning oder Erklärvideos: Murf.ai liefert ruhige, professionelle Sprecher-Stimmen mit feiner Steuerung.
- Du produzierst Social-Media-Videos: Fliki kombiniert die meisten deutschen Stimmen mit einem Videoeditor.
- Du willst nichts ausgeben: TTSMaker oder der Edge-Browser reichen für gelegentliche Voiceovers.
- Dir ist Datenschutz wichtig: Coqui XTTS oder Kokoro laufen lokal, deine Daten bleiben bei dir.
- Du brauchst Avatar-Videos: Synthesia macht aus deinem Skript ein Video mit sprechender Person.
Und noch ein letzter Tipp:
Teste mehrere Tools mit deinem eigenen Content, bevor du dich festlegst. Fast alle bieten kostenlose Kontingente, und gerade bei der deutschen Aussprache gibt es von Tool zu Tool spürbare Unterschiede. Welches Tool im direkten Vergleich am besten klingt, hörst du in meinem ausführlichen Test der besten KI-Sprachgeneratoren.





